Looks like I didn't do this last year... but the year before you got a 10 year retrospective, so I'm not too worried. ;)
(Oh, looks like I did it on Twitter last year.
https://twitter.com/Tursilion/status/1345228785629556736
Oh well, I already started this here...)
It's hard to believe it's only been a year since I settled in up here -- and it's also hard to believe it's only been a year. I actually applied for a number of jobs, and it surprised me how much I dislike interviewing. ;) I guess, in fairness, I only had three jobs in the US that whole time, two of which I knew what I was doing, and one which was so amazing I'd do anything. (Also an honorable mention that I would have taken, they were awesome but fell into the 'knew what I was doing' bit...)Anyway, THIS year... well, applied for a handful of jobs. One was pretty exciting - they were a manufacturing robot company and I could have kept using my skills, but they declined. I felt like maybe I offended them with some of my questions about the hardware... got to remember not to question the design until AFTER hired... ;)

Amazon chased me for a while - through the year in fact. But I never ended up agreeing to the full interview process. Maybe someday. They were smart when I interviewed down south...
I ended up working on a gas detection camera instead - and that was a whole new world for me. ;) In the end, my own contribution was entirely on the Linux software side, but it was a neat little world that I completely was not aware of.

All I can say is my taxes are going to be fascinating this year... :p
But this usually isn't about boring old work. Unfortunately, it was a really quiet year for me. The pandemic forced a lot of things to be help back, and since I took work I didn't get /any/ of the personal progress I was hoping for.

I got my car side window smashed for the first time ever. They didn't take anything, just rifled through and left it all on the seat. They stole my neighbor's car, and there's some suspicion they were looking for spare keys. Still cost me $500. I was surprised, though, I park within inches of a concrete wall, yet that's the side they smashed the window and crawled into the car on. I can't even fit there - I can't imagine how skinny the thief was.
What made it doubly annoying was only two nights earlier, they had gone through my car again. Apparently that night I left it unlocked by accident. Again, took nothing, just left it on the seat. They already knew there was nothing there, why smash my window? I was really annoyed cause I had considered putting a webcam on my car dash, but I couldn't figure out how to power it.
I sadly don't have the pictures anymore - there was nothing in them I wanted to keep.
I actually talked to Natsume about licensing Double Dragon, to try for another retro port. They were friendly but eventually declined. Doing ports legally is kind of neat but it IS hard to get people to talk to you. ;)
Got my COVID shots, of course -- ended up with 3 of them! I got AZ first, and when that was declared no good for travel, I was able to get two moderna shots to cover that. All three shots made me feel lousy for a day, yes. But now I'll never know if I actually had it when I was in Asia. ;)
I got a lovely final gift from Tokyo Disneyland - one of those laser printed 3D engravings inside a glass cube of the rose from Beauty and the Beast, with my name and thanks for helping with the attraction. I am looking forward to finally being able to fly back to Tokyo and visit the park as a guest, someday. :)

I've continued working with the Second Life wrestling group, though Second Life had several bouts of the usual internet drama. We seem to have survived them, and for a little while I even refereed
a second federation, using a grump gryphon character I had created for earlier stories.

We also did a big charity event called Slam-O-Ween, part of a week long series of events on SL for Breast Cancer. I dressed my raccoon ref up as Elvira for that one. We raised 3/4s of a million "Lindens" over the entire event (about $3500 US), with our silly little animal wrestling accounting for a double-digit percentage of that.

I also ended up aging up my old TLK Muck wizard hyena pup, and now he's a wrestler too. ;) I got permission from the person who created a lot of the original lore that he ended up in, and am using it as his gimmick. ;) I'll be honest, there was a significant time investment here... but I was lucky enough to get help from a skin designer and even from a talented singer/songwriter and friend for her music.


I did some minor updates to Classic99, and I did some minor updates to my ponyscript, some updates to my VGM player, but precious little else, honestly. I let myself get overwhelmed again - and so quickly. The ONE task on my TODO list was Classic99 V4, and I'm going to try to meet that by the end of the year by the letter of the law, if not the spirit. (That is, my goal is 'boots', not 'useful'. ;) )
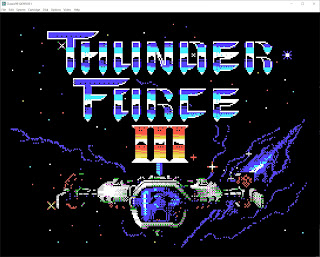
Oh! I did sidetrack and make a tribute to Thunder Force III on the TI - converting all the music with my VGM toolchains and creating some of the intro graphics to resemble it!
I did take one trip out to Ottawa, right before Omicron became the new buzzword, and it was nice! But it felt so weird to be flying after so long. ;) I didn't take any pictures at all...
I also let Cool Herders DS leak out to an archive site, just to see if that gets a single person to play it and comment on it. (Nope. Not yet. I actually thought this version was fun... ;) ). That's over here:
https://www.gamesthatwerent.com/2021/11/cool-herders/
And of course someone immediately posted it with invalid license terms over to Archive.org... well meaning perhaps, but bad form. Still... here's that:
https://archive.org/details/cool-herders-beta-90-percent
Plans are in place for next year to be more productive - if the new job doesn't crush me. They both promise my weekends will be fine and that the work will be super challenging. This will be interesting. ;)
So yeah, that was 2021!